WuxiaWorldTextAnalyser
This repository contains analysis tool of text found in English translation of Chinese fantasy novels and light novels posted in WuxiaWorld. All text data belongs to WuxiaWorld.
How to use?
All scripts are located in script/ directory. Run the scripts in the following order:
-
Sample text extraction: textSample_extraction.m Set novel ID Line 12 and run once to extract text and store in text_sample/ directory. Alternatively, already extracted sample text in the directory can also be use.
-
Choose novel title Line 3 to use for network training in textSample.m. This script will be loaded in the subsequent script execution to take the sample text from text_sample/ directory.
-
Train LSTM network to generate text word-by-word: LSTMnet_train.m The trained network will be saved in trained_network_sample/ directory.
-
Generate new text based on trained network: textGenerator.m.
-
[Optional] If the network training was interrupted, run LSTMnet_train_resume.m to resume the training. You can reduce the maximum number of epochs and adjust other training options, such as the initial learning rate.
-
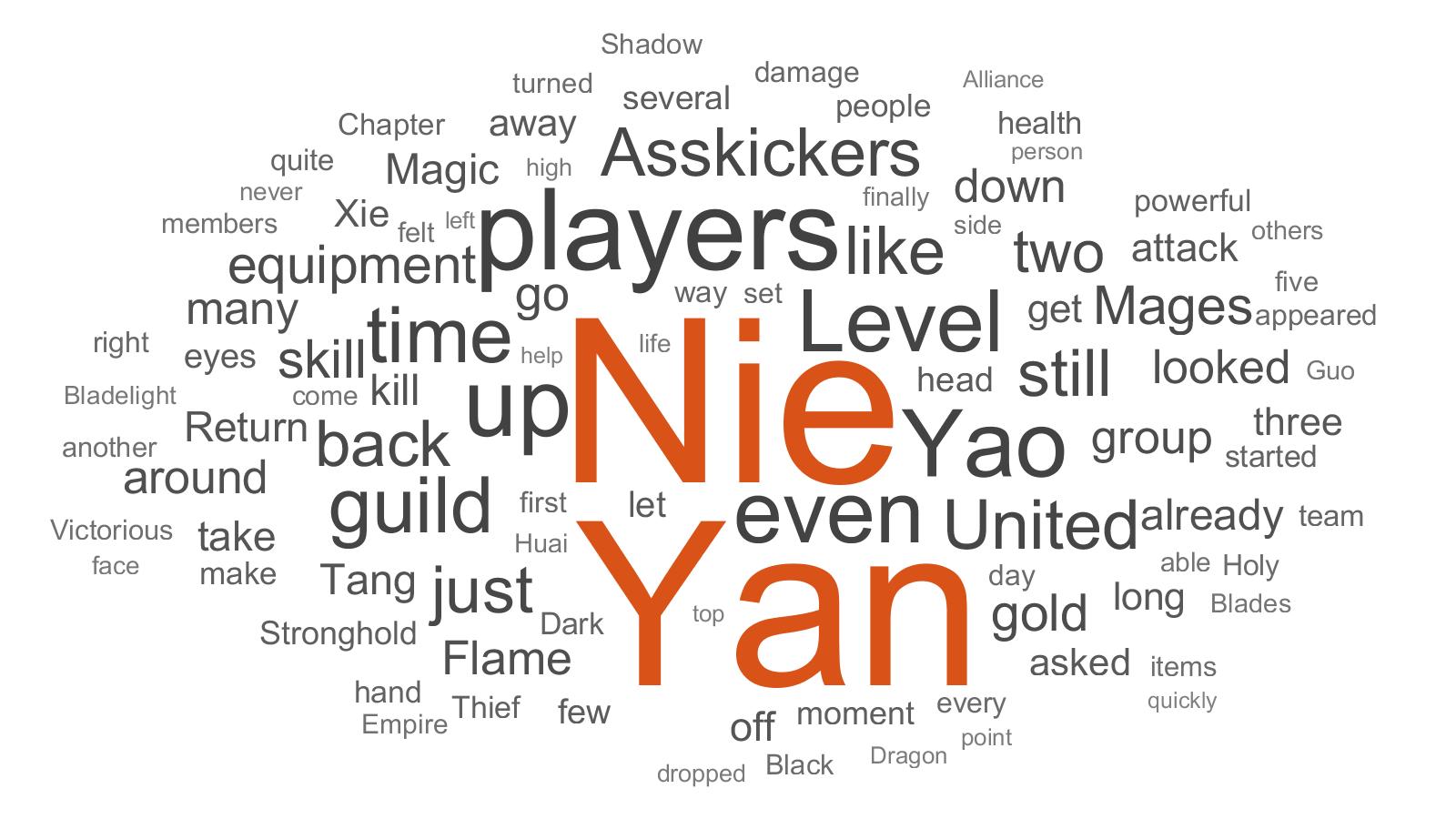
[Optional] Word cloud chart can be generated with textWordCloud.m. The generated image will be saved in images/ directory.
Examples
- A World Eternal word cloud chart:
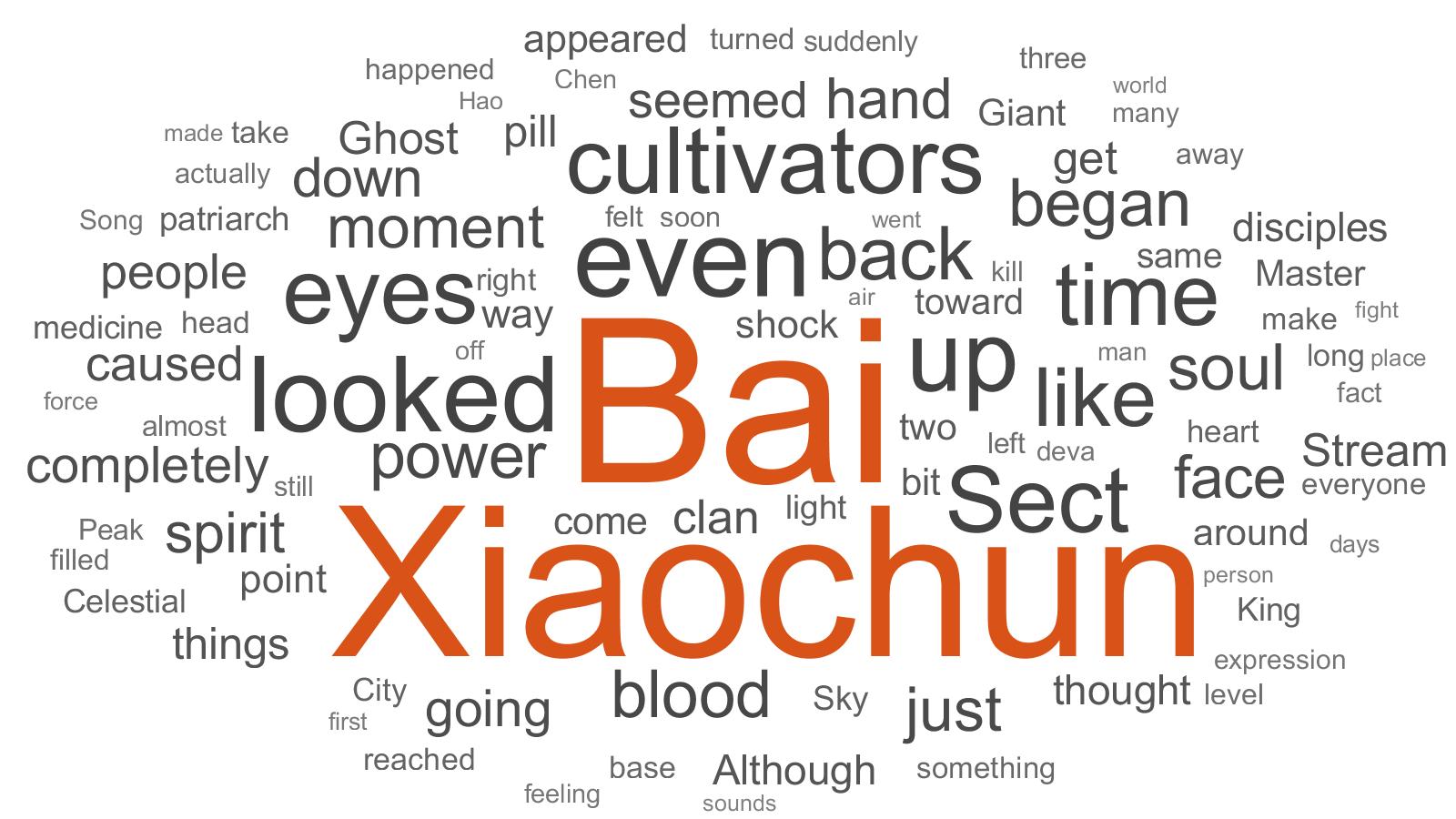
- Rebirth of the Thief who Roamed the World: